ILMSImage Classification
Índice |
 ILMSImage Classification
ILMSImage Classification
Introdução
O ILMSImage Classification faz parte do ILMSImage plugin for QuantumGIS e, neste contexto, realiza uma análise temática em duas etapas, compreendendo classificação não-supervisionada e supervisionada.
Como vários painéis ILMSImage consistem de dois componentes, o ILMSImage Project Information verificar se há link em português na parte superior e as ferramentas em si na parte inferior.

Classificação temática
Antecedentes
O processo de classificação temática dentro do ILMSImage é composto por três sub-tarefas, (1) uma classificação não supervisionada das células existentes e as suas características como classes de tipo celular, (2) a definição de referência ou áreas de formação, usando uma camada de dados vector e (3) a classificação real temática que é baseada nos resultados de ambas as tarefas anteriores. Abaixo cada passo é apresentado e descrito em detalhe.
Classificação não-supervisionada em classes de tipo celular
A classificação não-supervisionada refere-se a geometrias geradas durante a Criação de Células e o cálculo de atributos para as geometrias com o intuito de derivar classes de tipo celular a partir de ambos os componentes. Esses formam um grupo de células que – independentemente da localização geográfica na imagem ou de um com relação ao outro – têm características semelhantes. Dito de forma simplificada, nesta tarefa por exemplo, células alongadas e escuras são separadas das que são bastante redondas e brilhantes - só que a decisão correspondente, na realidade, não se limita às características nomeadas mas baseia-se em todas as características geradas durante o cálculo de atributos. O conceito básico da presente tarefa corresponde, portanto, à análise de agrupamento divisivo. (# Partitional_clustering | Cluster Analysis – em português: - Clustering).
O ILMSImage implementa dois métodos de análise de cluster:
- Um algoritmo k-Means, que representa um método freqüentemente utilizado para encontrar estruturas em grandes quantidades de dados. O número de aglomerados, os quais devem ser encontrados, é determinado previamente. Depois de uma inicialização aleatória cada célula é atribuída ao cluster, de qual o vetor característico central é o mais semelhante à célula. Se esta atribuição inicial for concluída, os centros de cluster são recalculados e cada célula é comparada novamente com clusters existentes. Estes passos são repetidos até que nenhuma das atribuições se altere novamente - a análise do cluster está concluída.
- Outro método para o agrupamento divisivo é o algoritmo de self-organizing maps (mapas auto-organisantes), que foi originalmente desenvolvido por Teuvu Kohonen. Trata-se de uma rede neuronal artificial que é capaz de projetar um espaço de características multi-dimensional, que funciona como uma fonte de dados sobre uma variedade bidimensional de valores. Esta característica explica a relação ao map. O funcionamento detalhado desse algoritmo é descrito em outro ponto.
As células criadas pelo ILMSImage e as suas características derivadas também representam um espaço de multi-dimensional características. Se este deve ser classificado de forma não supervisionada, ou seja por clustering, esta opção precisa ser ativada na parte correspondente do painel de classificação de ILMSImage. Por tipo um dos dois métodos acima mencionados pode ser selecionado, o parâmetro tolerance (intervalo de valores de 0,01 a 0,50) controla a sensibilidade dos processos. Um valor mais alto corresponde a uma maior variabilidade de características aceitável dentro dos aglomerados que estiverem sendo gerados – o que implica na diminuição do número destes. Um baixo valor de tolerância gera um elevado número de classes, uma vez que a variabilidade de características aceitável dentre aqueles é menor.
O processamento contínuo é indicado por uma janela correspondente. De acordo com o número de atributos selecionados e com a sensibilidade selecionada, a duração do tempo de cálculo pode variar muito. Após a conclusão bem sucedida do processo, o usuário é informado sobre o número de classes de tipo de células geradas:

Se a caixa de seleção Unsupervised classification permanece ativada, um clique sobre Visualize results pode carregar o resultado da classificação não-supervisionada para a visualização do mapa atual. As cores utilizados para a visualização são aleatórias, isto é que não possuem qualquer significado semântico em relação à classe temática de uma célula. Elas apenas ilustram a sua pertença comum a uma classe tipo de célula. Na chave do camada de dados raster aparece no grupo ILMSImage Exports especificado como <project name>_sample.

Deve notar-se que apenas um resultado pode existir nesta tarefa, o qual pode ser utilizado para classificação temática adicional. Se um tal resultado não foi visualizado após a sua geração como descrito acima, a camada de varredura mostrada na visualização do mapa mais provável não corresponde a esta base de dados.
Definindo Áreas de Referência
Áreas de referência e de treinamento podem ajudar o usário a definir o esquema de classificação apropriado para seu objetivo e transmití-la para o ILMSImage. As áreas separadas e os seus atributos são retirados da camada de dados vetor, particularmente de um shapefile. A tabela de atributos do presente ficheiro tem de corresponder a um determinado formato - para permitir a importação correcta – o o que é descrito abaixo.
| Nome do campo | Tipo de dados do campo | Descrição |
|---|---|---|
thema |
Inteiro | Número de identificação clara das classes de referência diferentes. É importante que a contagem comece com um e seja consecutiva. |
desc |
String | descrição verbal da classe de referência. É basicamente um campo que é informação opcional, mas pode ser visto como uma boa prática para dar nomes às classes de referência que de outra forma são definidas apenas por números. |
O shapefile pode ter campos adicionais - para criar um conjunto de dados de referência válida, é suficiente que ambos os campos acima mencionados possam ser encontrados na tabela de atributos. Desta forma, basicamente, todos os shapefile de área - incluindo modificações necessárias - podem ser usados como referência para o ILMSImage.
A fim de facilitar a geração de um novo conjunto de dados de referência para o usuário, o QuantumGIS plug-in disponibiliza um shapefile correspondente que tem a estrutura correcta e pode ser complementado com fronteiras de área e suas atribuições. A função pode ser ativada clicando-se em Create reference layer template, depois de toda a seção Reference data import ter sido ativada usando a caixa de seleção correspondente. O diálogo a seguir requer o nome do arquivo que deve ser gerado (a configuração padrão é <project name>_ref) e pede ao usuário para determinar o número estimado de classes temáticas. Esta indicação não é final, subsequentemente classes podem ser adicionadas ou removidas - a única função é disponibilizar o número determinado de classes (com representação visual diferente em termos de cor) para a definição das zonas de referência.

No caso do conjunto de dados de referência que deve ser gerado já existir, o usuário será informado e convidado a tomar uma decisão:

Quando a camada tiver sido gerada, ela aparece na visão geral do projeto QuantumGIS atual. Lá ela também pode ser transferida para um modo editável clicando-se no botão direito do mouse e selecionando Bearbeitungsmodus umschalten (mudar o modo de edição).Isso é necessário para registrar as geometrias das áreas de formação e sua atribuição ao conjunto de dados de referência.

Agora, a ferramenta Polygon digitalisieren(digitalizar polígono) pode ser usado para gerar novas áreas de referência. Isso geralmente acontece quando se acessa dados da imagem original. De acordo com o esquema de objetivo e classificação, outras visualizações também podem gerar boas indicações para as fronteiras de áreas de formação. A imagem seguinte ilustra um detalhe da geração de uma área de referência para a classe de estabelecimento Settlement/Siedlung. .
- Primeiro, os pontos de suporte do polígono são gerados ao clicar-se com o botão esquerdo do mouse nas coordenadas correspondentes. Não é necessário ser muito preciso, já que o ILMSImage é capaz de separar periferias potenciais de áreas centrais de uma área de referência por critérios estatísticos. Em vez de ser preciso, muitas vezes, faz mais sentido aumentar a amostra, gerando várias áreas de referência para uma classe temática.
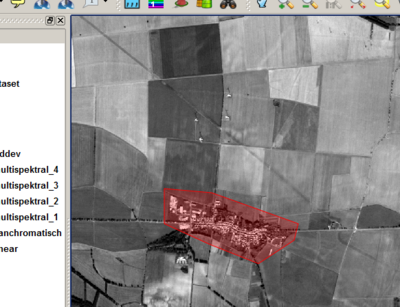
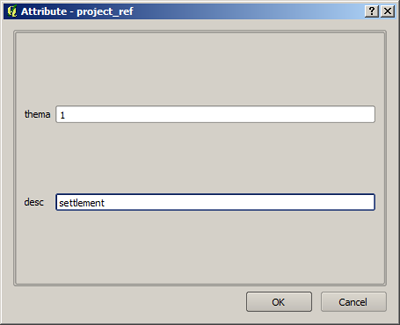
- Quando todos os pontos de apoio são definidos, um clique com o botão direito do mouse termina a digitalização do polígono. A máscara de entrada seguinte à identificação de classe e a descrição correspondente são indicadas. Deve notar-se novamente que a numeração das classes começa a partir de um e tem de ser consecutiva.
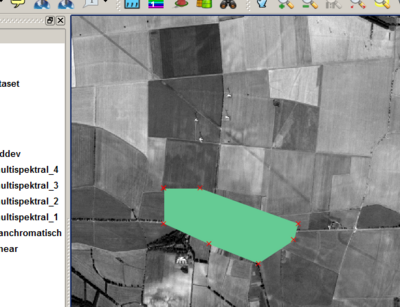
- Após a confirmação da máscara de entrada, o polígono é mostrado na cor que é aleatoriamente selecionada para este ID.
- É de utilidade modificar a cor da representação de acordo com os fatos, para que ou a auto-plausibilidade seja estabelecida (floresta = verde, água = azul) ou o uso comum de determinadas cores (Povoamento = vermelho, agricultura = cor-de- terra) seja aplicado. Utilizar o modelo descrito acima significa não ter mais que ajustar a representação da camada, mas apenas a cor de cada um das classes temáticas. A janela requerida pode ser acessada clicando-se com o botão esquerdo do mouse na cor a ser modificada. Lá também a designação pode ser atualizada (de reference class 1 para Settlement (Povoado)).
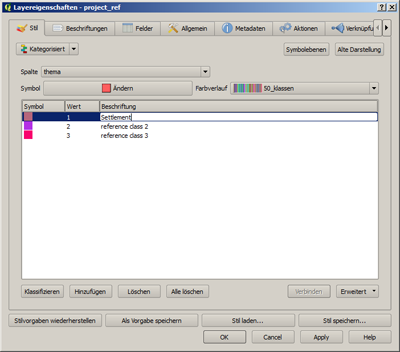
- O resultado é uma área de referência primeiro de uma classe temática específica, a exemplo ilustrado mostra a classe Settlement/Siedlung (Povoado).
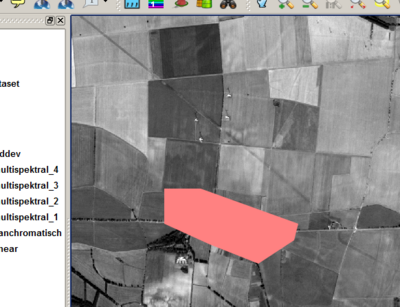





O procedimento acima descrito é repetido até que um número suficiente de áreas de referência foi definido. A comutação repetida e a confirmação da seguinte janela de diálogo salva o conjunto de dados de referência. Se as cores e denominações das classes são modificadas também, o exemplo do Rot mostra a seguinte imagem:

Importando áreas de referência
A fim de tornar o conjunto de dados de referência definido adequado para a classificação temática, ele tem de ser importado para o projeto ILMSImage. Isto significa, em primeiro lugar, que os dados têm de ser carregados no projeto QuantumGIS atual - não importa como ele foi gerado. Na caixa de lista Reference data layer todos os níveis vetor carregados são listados, os quais têm a estrutura acima descrita e podem ser importados pelo ILMSImage. Após a camada necessária tiver sido selecionada, ao clicar-se em Conduct classification inicia-se a importação de dados de referência. Isso transforma o conjunto de dados vetor no formato raster e o adiciona à lista de atributos das células, o que normalmente acontece rapidamente. O resultado completo pode ser representado na visualização do mapa atual, clicando-se em Visualize results. O resultado para o exemplo acima descrito de um conjunto de dados de referência pode ser como o da seguinte imagem (sujeito às geometrias de células subjacentes):

O processo aplica as cores utilizadas para a visualização diretamente a partir da representação da camada de dados vetor correspondente. Para uma melhor diferenciação das classes temáticas é recomendado se utilizar cores diferentes para essas quando são definidas. Se elas são auto-plausíveis ou correspondem à associações comuns (veja acima), um reconhecimento rápido do conjunto de dados de referência em formato raster - e um resultado posterior da classificação real - está garantido.
Classificação Final
A caixa de seleção Supervised classification ativa a última tarefa no contexto do painel ILMSImage para a classificação temática. Para este efeito os resultados da análise de agrupamento e da importação de dados de referência estão ligados um ao outro.
O resultado final da classificação está disponível em formato raster como um arquivo GeoTIFF para permitir comparabilidade máxima.
