Spatially distributed environmental models generate a lot of spatio-temporal data. To work with these data effectively it is usually necessary to aggregate it and to visualize it in maps.
This article shows how JAMS can be used to aggregate spatio-temporal data and to save the result in a shapefile. To demonstrate the work flow, a map of yearly mean precipitation is generated for the Wilde Gera catchment with the model J2000. This model is shipped with every JAMS installation.
Preparing and running the model
Start by opening the model in the JAMS User Interface Configuration Editor (JUICE) and have a short look at the model structure. The model has a J2k model context, which contains the temporal context “TimeLoop”. A spatial context named HRULoop is nested in the TimeLoop. The precipitation values are stored in the attribute “precip” within the HRULoop context (see figure 1).
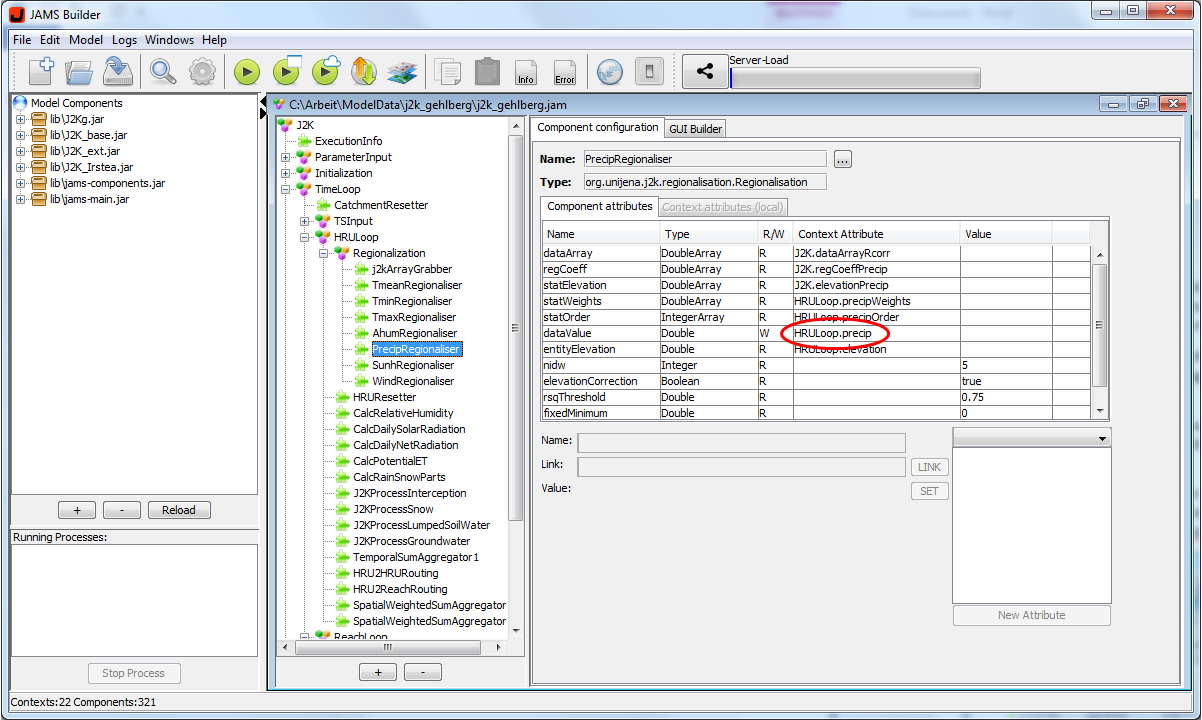
Figure 1: Structure the model J2000 applied on the catchment Wilde Gera
Now ensure that the spatially distributed precipitation data, calculated by J2000, is actually saved in a file. For that purpose, use „Configure Modell Output“ ![]() from the toolbar. The datastore editor dialog will show up, which allows you to configurate the model outputs (see figure 2). On the left side of the dialog you see a list of all contexts within the model. By selecting a context in the list, its attributes are shown in the list on the right side of the dialog. To enable outputs for the spatial context tick “HRULoop” on the left side. With the plus and minus button you may add the precip and area attribute to the list and delete all other attributes as it is shown in figure 2.
from the toolbar. The datastore editor dialog will show up, which allows you to configurate the model outputs (see figure 2). On the left side of the dialog you see a list of all contexts within the model. By selecting a context in the list, its attributes are shown in the list on the right side of the dialog. To enable outputs for the spatial context tick “HRULoop” on the left side. With the plus and minus button you may add the precip and area attribute to the list and delete all other attributes as it is shown in figure 2.
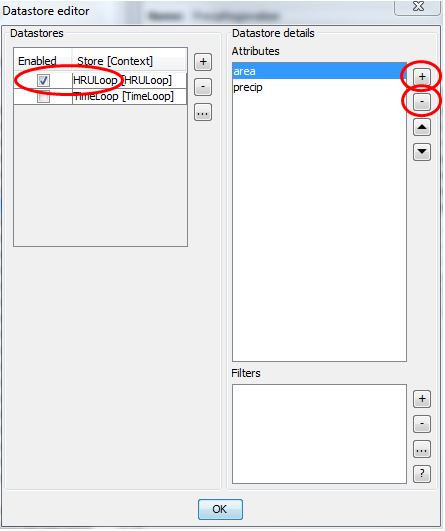
Figure 2: Datastore editor
Now start the model. The execution will take a moment (23 seconds on my maching), because saving the large amount of data requires some time. The results are saved in a file named HRULoop.dat which is located in the output directory.
Using JAMS Data Explorer (JADE)
After the model finished its simulation open JAMS Data Explorer (JADE) ![]() from the toolbar. When JADE showed up, you should see the HRULoop.dat on the left side already. Double-click on HRULoop.dat to open it. Now you should see a data view as shown in figure 3. Region (1) shows all attributes within the selected file. In our case it contains only two attributes namely area and precip. Region (2) shows for which time steps data is available. J2000 is a daily model and in my case the simulation was carried out from 1996-11-01 to 2000-10-31. Therefore the lists contains 1461 entries, one for each day. Region (3) lists the IDs for all spatial modelling entities. For the Wilde Gera catchment 614 entities are used. In Region (4) several functions are available to process the data. Select all entities and select a time step. Then press the button “Time Step”. This will generate a table in Region (5). The first column of the table shows the IDs of all entities. The second column shows the precipitation value for each of these entities.
from the toolbar. When JADE showed up, you should see the HRULoop.dat on the left side already. Double-click on HRULoop.dat to open it. Now you should see a data view as shown in figure 3. Region (1) shows all attributes within the selected file. In our case it contains only two attributes namely area and precip. Region (2) shows for which time steps data is available. J2000 is a daily model and in my case the simulation was carried out from 1996-11-01 to 2000-10-31. Therefore the lists contains 1461 entries, one for each day. Region (3) lists the IDs for all spatial modelling entities. For the Wilde Gera catchment 614 entities are used. In Region (4) several functions are available to process the data. Select all entities and select a time step. Then press the button “Time Step”. This will generate a table in Region (5). The first column of the table shows the IDs of all entities. The second column shows the precipitation value for each of these entities.
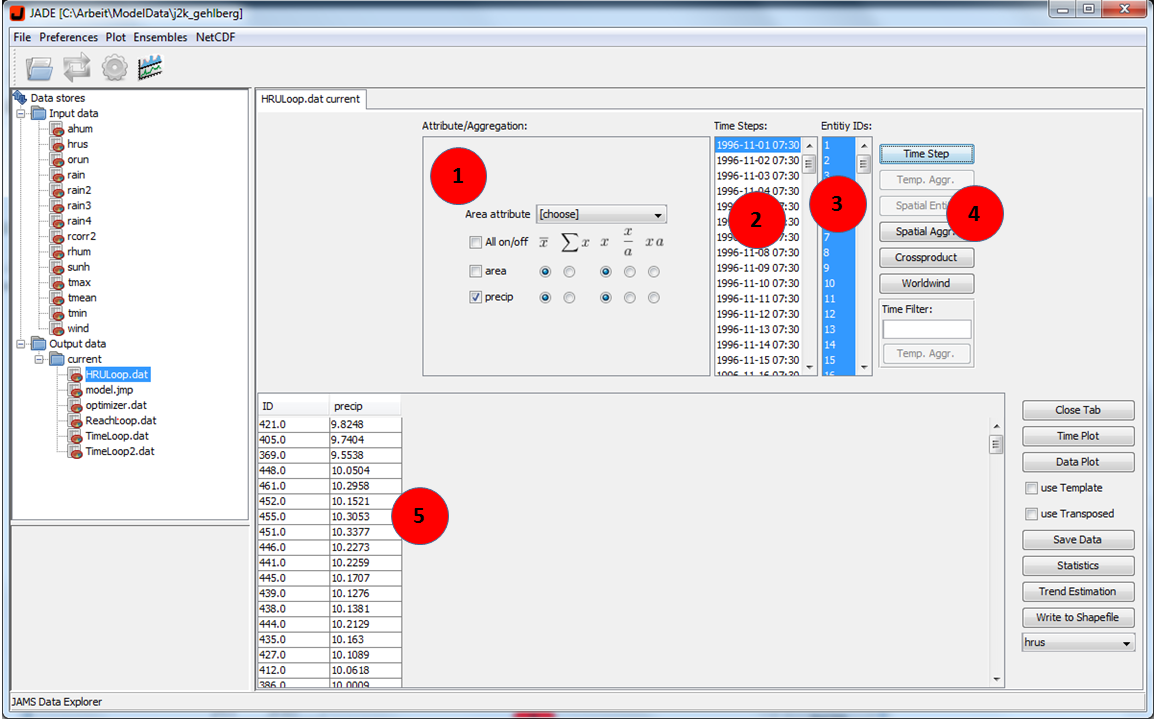
Temporal Aggregation
Usually, it is not sufficient to inspect a single timestep. Instead you may want to aggregate the data. This can be done by using the Time Filter feature. You can type SQL expressions with wildcards to select dates automatically. SQL knows different wildcards listed in the table below:
| Wildcard | Description |
|---|---|
| % | A substitute for zero or more characters |
| _ | A substitute for a single character |
This can be used to aggregate various time steps. The next table shows some examples:
| Expression | Description |
|---|---|
| ____-01% | Selects all time steps in January |
| 1997% | Selects all time steps of 1997 |
| 199% | Selects all time steps from 1990 to 1999 |
To get the yearly mean of precipitation for the year 1997 we type
1997%
into the Time Filter field and use the Temp. Aggr. button.
Export data to a shapefile
At last the aggregated data can be exported to other software. You may simply drag and drop the data to e.g. Microsoft Excel. Alternatively you can export the data to a text file or to a shapefile.
To save the data in a textfile just use the “Save Data” button. A dialog will show up, allowing you to select the location and the name of the output file.
To save the data in a shapefile you may use the button “Write to Shapefile”. To use this function you need a suitable shapefile datastore in your input directory. This shapefile datastore should contain the spatial modelling entities. If you have several shapefile datastores in your input directory you can select the right datastore in the combobox below the buttons.
When saving the data to a shapefile a message will show up telling you that JAMS is trying to create that shapefile (see figure 4). If this was successful, you will see a message about the fields attached to that shapefile and finally a success message in the end (see figure 5).

Figure 4: JAMS is trying to create a new shapefile

Figure 5: Shapefile export was successful
After that you can work with the newly created shapefile in a GIS software of your choice (see figure 6).
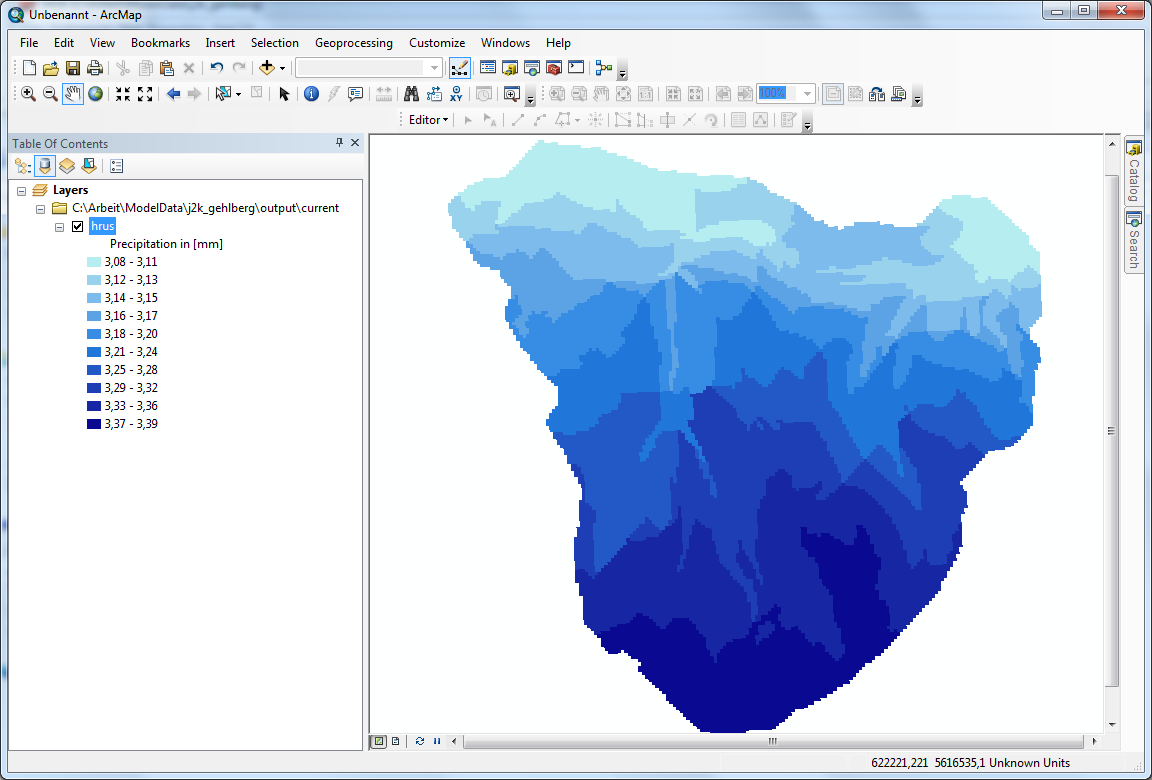
Figure 6: Opening aggregated data in ArcGIS
Cheers
Christian