Tutorium Monte Carlo Analyse
Der JAMS Data Explorer (JADE) bietet eine mächtige Werkzeugsammlung für die Monte - Carlo - Analyse von Umweltmodellen. Dies beinhaltet Methoden zur Sensitivitätsanalyse, Unsicherheitsanalyse und Visualiserung von Datensätzen, basierend auf der Monte - Carlo - Toolbox (MCAT), die von T. Wagener (??) entwickelt wurde.
Voraussetzung für die Anwendung der meisten MCAT Methoden ist ein vorangegangenes Monte - Carlo - Sampling, das heißt häufig wiederholte Anwendung des zu analysierenden Modells mit gestörten Parameter- und Eingabedaten. Um diese Aufgabe zu erfüllen existieren mehrere RandomSampler Komponenten, die ausführlicher hier [?] erklärt werden.
Das Resultat des Samplings ist eine Zusammenstellung der Modellantworten, die aus Modelparametern, Gütekriterien, skalaren Modellergebnissen sowie räumlichen und zeitlich aufgelösten Datensätzen bestehen können.
Bei der Arbeit mit Ensembles entstehen oft riesige Datenmengen, deren Verarbeitung hohe Rechenzeit- und Speicheranforderungen bedarf. Da, das allgemeine JAMS Datenkonzept hierbei an seine Grenzen stößt, wurde mit Hinblick auf
- Effiziente Datenspeicherung unter Berücksichtigung des Speicherbedarfs
- Schnelle und einfache Erstellung von Ensembles aus Rohdaten
- Flexibilität und Erweiterbarkeit im Sinne von Datentypen
- Einbettung von Metadaten
entwickelt.
Um einen Ensemble Datensatz zu erstellen, wird wie folgt vorgegangen.
Wählen Sie im Menü Datei den Eintrag Erzeuge Ensemble. Sie sehen nun folgenden Dialog

Klicken sie nun auf die Schaltfläche Laden um eine JAMS-Modellausgabendatei (z.b optimizer_wizard_J2K.dat) auszuwählen. Nachdem Sie eine Datei gewählt haben, werden alle enthaltenen Datensätze aufgelistet. MCAT unterscheidet zwischen vier verschiedenen Datentypen: Parameterwerten, Gütekriterien, skalaren Modellausgaben und simulieren und beobachteten Zeitserien. Da diese Information nicht explizit in den Modellausgaben enthalten ist, müssen Sie diese angeben.
Allerdings sind für viele Anwendungen bereits Standardwerte hinterlegt, die die Arbeit erleichtern.

Sie können beliebige weitere Datensätze zu dem Ensemble hinzufügen. Achten Sie aber darauf, dass nicht jede Zusammenstellung semantisch korrekt ist. Zum Beispiel ist die Verknüpfung von unterschiedlichen Monte - Carlo - Samplings ist im Allgemeinen nicht sinnvoll. Zum Abschluß beenden Sie den Dialog mit "OK". Sie werden nun aufgefordert die Ensemble-Datei zu speichern. Speichern Sie diese im gleichen Verzeichnis in dem sich auf die anderen Modellausgaben befinden (z.B. workspace\output\current\) Öffnen Sie nun den entsprechenden Workspace und klicken sie doppelt auf die Ensembledatei. Es öffnet sich nachfolgende Unterfenster, welches die wichtigsten Informationen über das Ensemble liefert. Dazu gehören die vorhandenen Datensätze, die Anzahl der Monte - Carlo - Simulationen, der abgedeckte Modellierungszeitraum und der verwendete Monte - Carlo - Sampler.

Monte Carlo Sampling
Monte Carlo Parameter Sampling ist ein Algorithmus, der wiederholte Modellsimulationen mit zufällig gewählten Parametrisierungen (nach einer festgelegten Wahrscheinlichkeitsdichte) durchführt. Um eine gute Reproduzierbarkeit und Genauigkeit der Ergebnisse zu erhalten, ist es wichtig eine gute Abdeckung des gültigen Parameterraumes zu erreichen. Dementsprechend ist es meistens eine große Anzahl von Samples notwendig. Dies kann eine sehr rechenaufwändige Aufgabe sein. Es ist bekannt, dass ein Monte - Carlo Sampling basierend auf einer Gleichverteilung der Parameter kann Milliarden von Samples produzieren ohne eine einzige gute Lösung zu erreichen (Stedinger et al, 2008). Falls viele Parameter analysiert werden sollen und a priori Wissen über das zu untersuchende System nicht in ausreichenden Maße vorhanden sind, ist es sehr wahrscheinlich, das der Rechenbedarf enorm ist, da Monte - Carlo Sampling offensichtlich unter dem Fluch der Dimensionen (Bellmann) leidet, d.h. die Anzahl der benötigten Samples zur Erreichung einer bestimmten Sampledichte steigt exponentiell mit der Anzahl der Parameter. konkrete Werte nachschauen
Anwendungen
Modellidentifikation
Jede Modellparamerisierung führt zu einer indivduellen Modellierung des realen Systems. Falls die Modellierung mit den Beobachtungen konsistent ist, lieft die Modellierung eine Erklärung der Beobachtungen, andernfalls ist die Modellierung ungeeignet. In vielen Fällen kann ein Modell, Beobachtungen in der Natur (beispielsweise Niederschlags-/Abflussverhalten) auf unterschiedliche Art und Weise erklären. Dieser Sachverhalt, der unter dem Begriff Equifinalität bekannt ist, zeigt sich unter anderem dadurch, dass unterschiedliche Parametrisierungen zu (scheinbar) gleich guten Modellen führen. In der Realität sind diese allerings oftmals nicht gleichwertig, da die vorhandenen Beobachtungen zwar gut erklärt werden, aber interne Modellzustände, die nicht validiert werden (können), teilweise oder völlig inkonsistent mit dem realen System sind. Letzlich erklärt sich Equifinalität dadurch, dass unterschiedliche System- und Modellzustände zu ähnlichen System- und Modellantworten führen können. Wäre es möglich jeden Modellzustand zu beobachten, würde das Problem nicht auftreten, da dies aber in der Praxis unrealistisch ist, ist es unmöglich zu entscheiden, welche Modellparametrisierungen tatsächlich korrekt sind und welche zurückgewiesen werden können. Equifinalität ist also keine Eigenschaft des Modells, sondern tritt erst in Verbindung mit Beobachtungen auf.
Die dadurch entstehende Mehrdeutigkeit, führt zunächst zu einer erhöhten Parameterunsicherheit, da aus den gegebenen Beobachtungen keine global eindeutige Parametrisierung abgeleitet werden. Folglich sollten möglichst alle (bzw. eine repräsentative Menge) der geeigneten Parametrisierungen für die Modellierung verwendet um den Einfluss der Unsicherheit in der Paramtrisierung auf die Modellantwort abzubilden (Wagener et. al, 2003). Hierfür ist es zunächst hilfreich festzustellen, welche Modellparameter eindeutig identifiziert werden können und welche nicht. Ein Modellparameter ist genau dann identifizierbar, wenn alle geeigneten Parameterwerte in einem relativ kleinen Bereich des gültigen Parameterintervalls liegen, wobei eine Parametrisierung geeignet ist, wenn sie zu plausiblen Modellantworten führt. Dadurch lässt sich ein Modell ist identifizierbar definieren, sofern dessen Parameter alle identifizierbar sind. In diesem Fall kann aus den Eingabe- und Messdaten eine eindeutige Parametrisierung abgeleitet werden. Detailierte Ausführungen bietet u.a. L. Ljung (1999).
Unsicherheitsanalyse
Im Kontext der Umweltmodellierung, kann Unsicherheit als Summe aus natürlicher Variabilität und Ungewissheit definiert werden. Die nachfolgenden Ausführungen sind angelehnt an Sayers et. al. 2002.
Natürliche Variabilität
Natürliche Variabilität ist eine Eigenschaft des Systems und bezieht sich auf den Grad von Zufälligkeit im Systems. Hierbei kann weiter zwischen zeitlicher und räumlicher Variation unterschieden werden. Beispielsweise ist es nicht möglich zu sagen, wann an einem beliebigen Punkt eines Fluss das nächste 100jährige Abflussereigniss beobachtet werden wird. Eine Zeit von 400 Jahren kann vorgehen ohne, dass ein 100jähriges Ereigniss beobachtet wird, allerdings könnten genau so gut zwei derartige Ereignisse innerhalb eines Jahres auftreten. Es ist nicht möglich natürliche Variabilität zu reduzieren.
Ungewissheit
Ungewissheit reflektiert das Wissen bzw. Unwissen über das System selbst. Beispielsweise beinhalten hydrologische Modele meist keine akurate mathematische Beschreibung aller im System relevanten physikalischen Prozesse. Grundwasserprozesse sind oftmals parametrisiert um das fehlende Wissen über die wahren physikalischen Prozesse auszugleichen. Das Modell beinhaltet daher selbst einen gewissen Grad an Ungewissheit. Im Gegensatz zu natürlicher Unsicherheit ist es möglich Ungewissheit zu reduzieren, beispielsweise indem die mathematische Beschreibung der Grundwasserprozesse verfeinert wird oder weitere Daten gesammelt werden, so dass das Modell die physikalischen Bedingungen besser präsentieren kann. Ungewissheit lässt sich allgemein weiter unterteilen in
Statistische Unsicherheit
Die Kalibration und Validierung von Modellen erfolgt an einer mehr oder weniger kleinen Menge von Beobachtungen, die aber auf jeden Fall endlich ist. Statistische Unsicherheit ensteht durch die Anwendung von Modellen in Situationen, die durch die bekannten Beobachtungen nicht abgedeckt werden. Diese Extrapolation tritt vor allem auf, wenn das Modell für lange Zeiträume von beispielsweise mehreren Jahrzehnten, zur Abschätzung von Extremereignissen und unter veränderten räumlichen Bedingungen angewendet wird. Diese Form der Unsicherheit ist abhängig von der Größe, Variabilität, Repräsentativität des verwendeten Datensazes und natürlich mit der statistischen Extrapolationsmethode verbunden. Beispielsweise ist normalerweise die Bestimmung eines 1000jährigen Hochwasserereignisses sicherer, wenn die Datengrundlage 80 Jahre umfasst und nicht nur 20 Jahre. Ein spezieller Fall der statistischen Unsicherheit ist die Parameterunsicherheit. Die meisten Umweltmodelle sind nicht parameterfrei, d.h. sie modellieren einige oder alle Prozesse nicht physikalisch exakt, sondern beschreiben den Prozess mehr oder weniger durch seine statistischen Eigenschaften. Je nach Grad der empirischen Beschreibung handelt es sich um ein statistisches oder konzeptionelles Modell. Je nachdem ob das Modell identifizierbar ist, können die Prozessparameter mehr oder weniger exakt bestimmt. Die Parameterunsicherheit drückt die Ungewissheit über den besten Parametersatz aus.
Prozessunsicherheit
Prozessunsicherheit lässt sich unterteilen in strukturelle Unsicherheit, d.h. die Unsicherheit, die mit der Verwendung eines bestimmten Modelles assoziert ist, und Datenunsicherheit. Strukturelle Unsicherheit resultiert aus vereinfachenden Annahmen über das reale System, derer das Modell zu Grunde liegt. Allgemein ist eine exakte Beschreibung eines natürlichen Prozesses ist nicht möglich, zum einen die räumliche und zeitliche Domäne diskretisiert werden muss und zum anderen muss die Modellierung über Teilprozesse durch eine statistische bzw. konzeptionelle Modellierung ersetzt werden, wenn das nötige Prozesswissen fehlt oder die Datengrundlage für eine Modellierung nicht ausreicht.
Datenunsicherheit
Datenunsicherheit bezieht sich auf Fehler in den Eingabedaten des Modells, die entweder durch Ungenauigkeiten in den Messungen (Fehlertoleranz eines Ombrometers), Unsicherheiten bei der räumlichen und zeitlichen Inter- und Extrapolation der Daten (z.B. Regionalisierung von Niederschlägen) und der Transformation der Daten entsteht (z.B. Umrechnung des Wasserstandes in Abflusses durch eine empirische HQ Beziehung).
Durch eine Analyse aller Unsicherheiten, ist es möglich herauszufinden, welche Unsicherheiten die Anwendung am meisten beeinflussen. Dies hilft zum einen abzuschätzen, wie robust und konfident Ergebnisse sind und zum anderen welche Maßnahmen zur Reduktion von Unsicherheiten getroffen werden sollten. Beispielsweise ist es für eine Hochwassermodellierung wenig nutzbringend, die Beschreibung des Grundwasserprozesses zu verfeinern (angenommen dieser liefert einen Beitrag von ca. 1% der Unsicherheit der modellierten Hochwasserspitze), wenn die Datenunsicherheit einen um eine Zehnerpotenz größeren Einfluss hat.

Sensitivitätsanalyse
Sensitivitätsanalyse ist die Untersuchung des Effektes von (kleinen) Änderungen der Eingabedaten und Modellparametern auf die Modellantwort (Saltelli et al 2000a, Beck et al 1994).
Es gibt einen engen Zusammenhang zwischen Parametersensitivität, Parameterunsicherheit und Parameteridentifizierbarkeit. Die Parameteridentifizierbarkeit gibt an, in welchen Grenzen sich geeignete Parameterwerte bewegen können. Sie definieren daher ein Intervall der gültigen Parametergrenzen. Die Parametersensitivität quantifiziert die Auswirkung von Änderungen des Parameterwertes auf die Modellantwort. Letztlich ist die Parameterunsicherheit der Modellantwort das Produkt aus der Größe des gültigen Parameterbereichs und der Sensitivität des Parameters. Senstivitätsanalyse kann aber nicht nur für Modellparameter, sondern für beliebe Modellvariablen und Eingangsgrößen verwendet werden, so dass eine Vielzahl von Anwendungen möglich ist. Sensitivitätsanalyse kann
- für die Modellvalidierung und Modellentwicklung bzw. -verfeinerung genutzt werden (e.g., Kleijnen, 1995; Kleijnen and Sargent, 2000;
Fraedrich and Goldberg, 2000).
- Einblicke über die Robustheit von Modellergebnissen bieten (e.g., Phillips et al., 2000; Ward and Carpenter, 1996; Limat et al., 2000; Manheim, 1998; Saltelli et al., 2000).
- als Werkzeug für die Priorisierung von Daten- und Forschungsbedarf genutzt werden (Cullen and Frey, 1999)
- für die Identifikation der dominierenden Elemente in einem natürlichen System in Bezug auf eine bestimmte Fragestellung
Methoden
Dotty Plot
Anwendung: Modellidentifikation, Sensitivitätsanalyse
Inputdaten: Parameter, Gütekriterium
Ein Dotty Plot ist ein spezielles Streudiagramm zur Prüfung auf Identifizierbarkeit von einzelnen Parametern und Sensitivität. Jeder Punkt repräsentiert eine bestimmte Güte, die mit einer speziellen Parameterkombination erzielt wurde. Für die Visualisierung wird der Parameterraum durch Auswahl eines Parameters auf eine Dimension projiziert. Die restlichen Parameter werden dabei ignoriert. Die obere Kante der Punktewolke repräsentiert eine Nährung für die beste Modellrealisation, die mit einem bestimmten Wert des ausgewählten Parameters erzielt werden kann. Falls diese Linie ein wohldefiniertes Maximum in einem schmalen Intervall aufweist, kann der Parameter als gut identifizierbar und sensitiv eingeordnet werden. Der Umkehrschluß ist nur bedingt möglich ein Fehlen des Maximums zeigt zunächst, dass der Parameter nicht ohne Weiteres identifiziert werden kann, trotzdem kann es sich aber um einen sensitiven Parameter handeln. Die beiden Abbildungen zeigen einen gut identifizierbaren eunen nicht identifizierbaren Parameter.

A Posteriori Parameter Distribution
Anwendung: Modellidentifikation
Inputdaten: Parameter, Gütekriterium
Der A Posteriori Parameter Distribution Plot kann mit Hilfe des Dotty Plots beschrieben werden. Zunächst werden die Gütewerte der Parameter 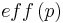 normiert, so dass sie als Wahrscheinlichkeit
normiert, so dass sie als Wahrscheinlichkeit 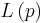 interpretiert werden können. Damit gilt für L(p)
interpretiert werden können. Damit gilt für L(p)
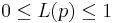
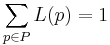
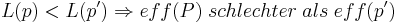
Die Parameterachse des Dotty Plots wird in mehrere gleich große Teilintervalle zerlegt. Jeder Punkt des Dotty Plots wird nun seinem entsprechendem Intervall zugeordnet. Für jedes Intervall Ik wird die durchschnittliche Wahrscheinlichkeit der zugehörigen Punkte berechnet. Das entstehende Balkendiagramm stellt damit die Wahrscheinlichkeit dar, dass der wahre Wert des Parameters in dem entsprechenden Intervall liegt. Ein Maximum Likelihood Schätzer würde nun, das Interval mit maximalen Wert als beste Schätzung für den Parameter annehmen. Ist der Parameter identifizierbar, sollte ein Balken mit hoher Wahrscheinlichkeit herausstechen. Die beiden Abbildungen zeigen einen identifizierbaren und einen nicht identifizierbaren Parameter.

Identifiability Plot
Anwendung: Modellidentifikation
Inputdaten: Parameter, Gütekriterium
Zunächst werden die Parametrisierungen des Monte - Carlo - Sampling nach ihrer Güte geordnet. Anschließend erfolgt eine Klassifikation der Parametrisierungen in geeignet und ungeeignet basierend dem gewählten Gütekriterium und einem statischen Schwellwert. In dieser Implementierung werden nur die besten 10% aller Parametrisierungen als geeignet eingestuft.
Genau wie bei dem A Posteriori Plot wird nun auch hier das Gütekriterium in ein Wahrscheinlichkeitsmaß überführt und dessen kumulierte Wahrscheinlichkeitsverteilung (F) berechnet.
Die Identifizierbarkeit des Parameters wird dann nach der Form von F bewertet. Falls die Darstellung von F eine gerade Linie zeigt, impliziert dies, dass die geeigneten Parameter über dem Parameterraum gleichverteilt sind. Dies ist ein Hinweis darauf, dass der Parameter schlecht identifizierbar
Im gegenteiligen Fall einer nicht linearen kumulierten Wahrscheinlichkeitsverteilung F
ist dies ein Hinweis auf einen besser identifizierbaren Parameter. Je enger und steiler die Kurve von
F umso besser ist der Parameter identifizierbar.
Die nachfolgende Abbildung zeigt den Idenfiability Plot einmal für einen gut identifizierbaren und einen nicht schlecht identifizierbaren Parameter.
